Quelques générations de natures mortes les plus simplistes possibles en utilisant des styles connus.
A painting of a bouquet of white roses on a black and white marble table, in the style of Alfred Stevens
Steps: 36, Sampler: Euler a, CFG scale: 7, Seed: 2486835856, Size: 768x512, Model hash: 7460a6fa
Parfois il ne faut pas trop brider le style naturel du peintre qui donne de meilleurs résultats:
A painting of flowers by Jan Davidsz de Heem
Steps: 24, Sampler: Euler a, CFG scale: 7, Seed: 4188331574, Size: 832x576, Model hash: 7460a6fa
A painting of an interior room by Jan Davidsz de Heem
Steps: 32, Sampler: Euler a, CFG scale: 7, Seed: 577309228, Size: 832x640, Model hash: 7460a6fa
A painting of grapes by Jan Davidsz de Heem
Steps: 32, Sampler: Euler a, CFG scale: 7, Seed: 2834515573, Size: 832x640, Model hash: 7460a6fa
Impact du sampler (technique)
Clairement, Euler_a et DPM2 par exemple donnent des « textures » différentes. Euler_a donne un aspect plus doux/vaporeux, DPM2 fait un peu plus vieilli ou rugueux. « DDIM » est un peu entre les deux.
A painting of grapes, apples, pears, basket by Jan Davidsz de Heem
Steps: 32, Sampler: Euler a, CFG scale: 7, Seed: 2200000539, Size: 832x640, Model hash: 7460a6fa
A painting of grapes, apples, pears, basket by Jan Davidsz de Heem
Steps: 32, Sampler: DPM2, CFG scale: 7, Seed: 2200000539, Size: 832x640, Model hash: 7460a6fa
img2img
Pour un meilleur contrôle de la composition, un img2img depuis un brouillon sous paint est probablement le plus efficace. Il faudra quand même affiner plusieurs fois le brouillon et les paramètres de denoise pour obtenir exactement l’effet recherché
A painting by Jan Davidsz de Heem
Steps: 22, Sampler: Heun, CFG scale: 7.5, Seed: 1440074437, Size: 704x576, Model hash: 7460a6fa, Denoising strength: 0.68, Mask blur: 4
Une exploration de reproductions de styles historiques.
« A painting by < artiste name > » sans autre guidage. Post-processing de correction de visages uniquement si nécessaire; sélection manuelle des meilleurs résultats (cependant la majorité est acceptable). Choix de la résolution en fonction du format le plus adapté pour chaque peintre.
Il apparaît vite que sans plus de précision, le réseau va se contenter de donner toujours des déclinaisons d’un seul exemple de sujet ou une composition, au lieu de piocher aléatoirement dans l’ensemble des thèmes disponibles de chaque artiste. Il faudra donc enrichir le prompt manuellement pour explorer le reste du répertoire.
tel-quel, ça donne donc plus un « style » de peinture (en terme de palettes et textures) qu’un répertoire de sujets.
S’inspirant d’un peintre professionnel ou pas, StableDiffusion reste approximatif sur les proportions et le nombre de bras d’un humain.
NB: il est possible que le sampler « Euler_a » soit plus adapté pour les styles « peinture » mais pas testé ici (et euler_a a tendance à changer trop de chose par rapport aux autres pour pouvoir comparer simplement)
Alfons Mucha
Le réseau connaît les différentes orthographes Alphonse/Alphons/Alfons Mucha , mais chacune semble donner des styles un peu différents.
Thomas Gainsborough
Deux variantes de prompts demandé, « painting » (qui ne sort que des paysages presque tous pareil) et « portrait« . Ça ne semble sortir que des auto-portraits cependant.
Edouard Manet
Les thèmes générés sont quand même plus répétitifs que les oeuvres d’origine (sans autre guidage de prompt)
Claude Monet
Une sur-représentation de L’étang aux nymphéas et autres sujets approchants.
Peter Rubens
Pas vraiment de variation entre « Peter Rubens », « Peter Paul Rubens » ou « Pierre Rubens »
Sur la composition récurrente qui sort à chaque fois, les amas de chair et les visages imparfaits donnent vite des visions d’horreurs…
De nouveau, test aussi sur « Portrait » explicitement mais qui sort toujours la même personne.
Alfred Stevens
Jan Davidsz de Heem
On voit bien tout de suite l’effet « nature morte » par contre en y regardant de plus près, difficile de savoir s’il s’agit de fleurs, de légumes ou de spatules en bois. Pour avoir un sujet cohérent il faudra raffiner le prompt pour guider la composition.
Johannes Vermeer
Une sur-représentation (voire une reproduction complète) de La Jeune Fille à la perle vient se greffer sur certains visages, ainsi que sa palette or & bleu. On remarque les variations du motif de carrelage au sol, similaire aux variations qu’on trouve dans les tableaux d’origine.
Pour les formats allongés, l’algorithme tend à créer des paires de personnage, à contrer en cochant « Highres Fix » dans l’interface.
Trigger-warning: bestioles en forme d’araignées à la fin de l’article
Dans cette startup, on se donne à 150% !
La syntaxe (mot-clef:valeur) permet de pondérer l’intensité d’un mot dans le prompt. Avec une personne connue, l’effet principal est de donner un contrôle de ressemblance entre « humain moyen » à 50% et « caricature des traits spécifiques » au delà de 100% (en fait, au delà de 90%, car la sur-représentation de certaines célébrités dans l’entraînement du réseau les exagère déjà par défaut)
Portrait photo of (Elon Musk:1.4)
Steps: 40, Sampler: DDIM, CFG scale: 7, Seed: 3355823348, Size: 512x512, Model hash: 7460a6fa
Alter-ego international
Un grand classique. Les traits ethniques vus par StableDiffusion appliqués à n’importe qui: Et si Elon Musk était Sud-Africain ?
Cocktail de célébrités
On commence par générer deux personnes avec les mêmes paramètres:
D’abord Thor, avec 90% de Chris Hemsworth
a photo of (chris hemsworth:0.9)
Steps: 42, Sampler: DPM2, CFG scale: 7, Seed: 1517168840, Size: 512x512, Model hash: 7460a6fa
Et Spiderman:
a photo of Tom Holland
Steps: 42, Sampler: DPM2, CFG scale: 7, Seed: 1517168840, Size: 512x512, Model hash: 7460a6fa
Mixage par << « machin » as « truc »>>
Première technique de mixage, par construction grammaticale du prompt: « machin » as « truc » pour avoir une sorte de 50%, plus ou moins selon les coefficients
a photo of (chris hemsworth:0.9) as Tom Holland
Bizarrement ça ne change pas grand chose, d’ailleurs je ne vais pas poster l’image.
À l’inverse si on échange les termes, il se passe quelquechose.
a photo of Tom Holland as (chris hemsworth:0.9)
On peut tenter de varier les coefficients pour avoir des résultats un peu chaotiques:
a photo of (chris hemsworth:0.7) as (Tom Holland:1.2)
Prompt-editing
La syntaxe de prompt [toto:tata:0.5] génère les toto sur les premières itérations, puis change la cible de génération à « tata » pour la fin (si je comprend bien). Une sorte de txt2img suivi d’un img2img automatisé, probablement.
a photo of [(chris hemsworth:0.9):Tom Holland:0.5]
a photo of [(chris hemsworth:0.9):Tom Holland:0.25]
Aussi changer l’ordre de qui est en premier est important:
a photo of [Tom Holland:(chris hemsworth:0.9):0.5]
Prompt-alternating
La syntaxe [toto|tata] , au lieu de répartir de la changement de prompt entre la 1ère et la 2ème moitié des itérations, l’alterne à chaque étape de génération. Du coup c’est aussi du 50% obligatoire sans autre coefficient possible. Cependant, en pratique ça n’a eu aucun effet pour le morphing de visages chez moi. Peut-être que les sampling-steps ou choix de diffuseur a un impact ?
a photo of [Tom Holland|(chris hemsworth:0.9)]
prompt vector interpollation
Théoriquement il y a moyen d’interpoller mathématiquement entre les représentations vectorielles des sujets demandés. Mais ça n’est pas encore implémentée dans l’interface actuellement disponible.
txt2img -> img2img
En renvoyant l’image de départ vers img2img et en changeant le prompt, et en réglant comme il faut le Denoising strength pour l’intensité de transformation, on peut avoir un résultat. Attention, la « seed » de l’img2img devrait être différente de celle du txt2img initial sinon il y a un effet de saturation qui dégrade l’image.
On peut aussi partir d’une vraie photo, probablement.
a photo of Tom Holland
Steps: 23, Sampler: DPM2, CFG scale: 7, Seed: 1016314451, Size: 512x512, Model hash: 7460a6fa, Denoising strength: 0.27, Mask blur: 4
Mi ours, Mi scorpion, et re-mi ours derrière
https://www.youtube.com/watch?v=Vwz9tX1cl5A
Au lieu d’un bête morphing entre deux humains, tentons de demander de hybrides improbables:
Le mi-ours était malheureusement impossible à générer directement à partir d’un prompt, et l’inpaiting ressemblait à un mauvais photoshop.
À la place:
A [zebra:wolf:0.3], National Geographics
Steps: 24, Sampler: DPM2 Karras, CFG scale: 7, Seed: 3167607957, Size: 768x512, Model hash: 7460a6fa
A [wolf:zebra:0.3], National Geographics
Steps: 24, Sampler: DPM2 Karras, CFG scale: 7, Seed: 3167607955, Size: 768x512, Model hash: 7460a6fa
A pig tiger
Steps: 24, Sampler: DPM2 Karras, CFG scale: 7, Seed: 3167607954, Size: 768x512, Model hash: 7460a6fa
A dolphin camel in the desert, by National Geographics
Steps: 24, Sampler: DPM2 Karras, CFG scale: 7, Seed: 3514664270, Size: 768x512, Model hash: 7460a6fa
girafphants
Spider-cat
Cryptozoologie
D’autres bestioles improbables, volontairement ou issues des tentatives infructueuses des paragraphes précédents ( « c’est pas ce que j’avais demandé, mais je garde quand même« )
« Alors c’est comme un centaure, mais Mi-cheval devant, Mi-cheval au milieu, et re-Mi-cheval derrière: »
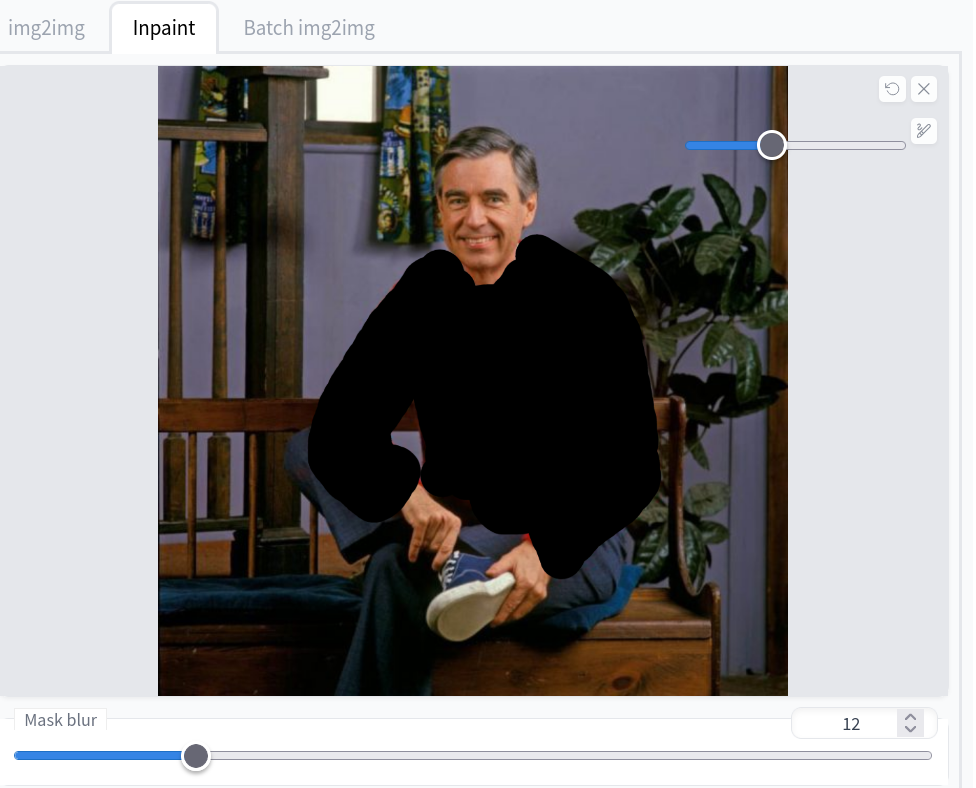
Image initiale: Mr. Rogers et son pull rouge (une vraie photo)
Sélection à la grosse louche du masque à appliquer:
Prompt d’inpainting: « A red wedding dress« . L’algo s’applique en gardant le contexte du reste de l’image non masquée, et décide donc que Monsieur Rogers porte plutôt des costumes d’homme que des robes:
Pour forcer le prompt, il faut donc rajouter le terme « woman » dans le prompt d’inpainting:
« A woman in a red wedding dress« .
Par curiosité on peut étendre le masque au visage pour voir comment l’algorithme a opéré la transition (Option « Restore Faces » de Automatic1111 activée)
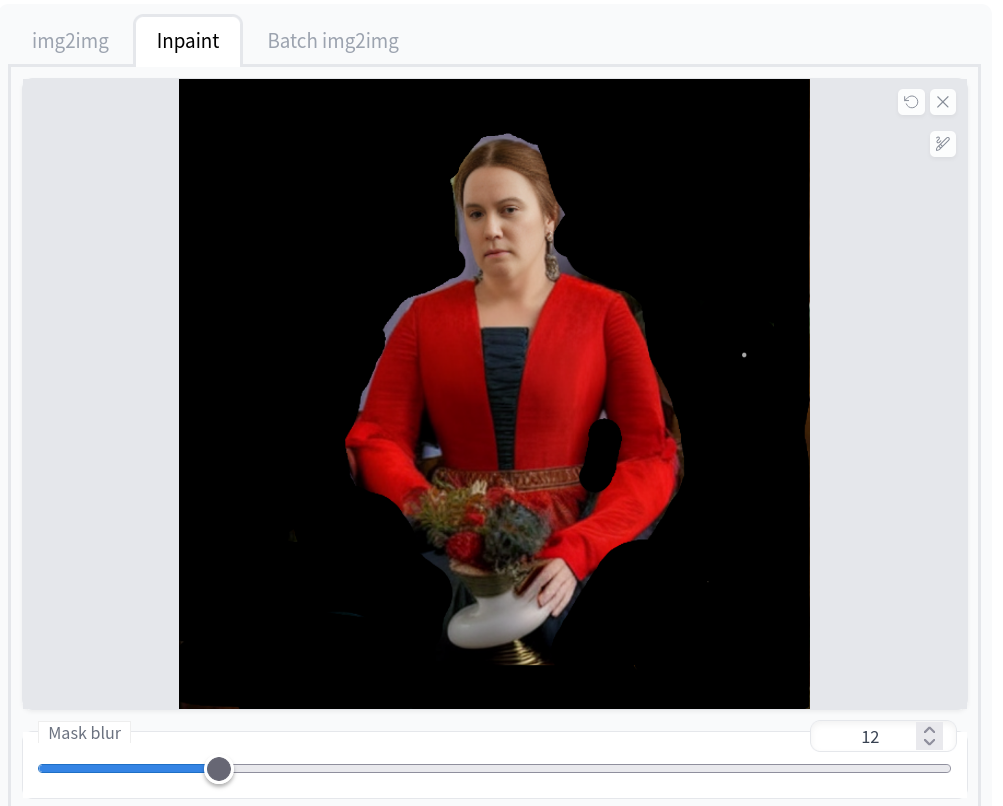
Cette semelle de basket n’a plus aucun sens, les trucs au dessus ressemblent à des fleur donc repartons d’ici pour la transformer en vase, avec un nouveau masque:
« A woman in a red wedding dress, holds a white porcelain flower vase«
Il est temps de finir le reste de l’image en transformant la plante verte, le rideau vert et les quelques meubles en bois, en quelque chose de plus intéressant. Masquage grossier:
« A woman sits on a dead tree log in a tropical forest »
les grands applats du mur de l’image d’origine ne fournissent pas assez de matière, il faut monter le curseur de « denoising strength » à 0.76 pour créer plus de chose à partir de rien:
L’anatomie des jambes est totalement à l’ouest. Les tentatives de regénérations des jambes ne donnent jamais rien avec cette position initiale, on va en faire autre chose avec ce bleu. Disons, « A blue giant bird«
Ça ne ressemble plus vraiment à un endroit où porter une « robe de mariage », on remasque le haut du corps pour en faire « an middle-aged warrior woman with dark red leather clothes«
Surprise ! Cette perruche et ce vase en porcelaine n’étaient qu’un habile camouflage pour une arme à dispersion énergétique !
« a sci-fi energy gun, with neon blue laser light, smoke«
« a red general in a cyberpunk city by night »
Ah, il est bien loin le Mr Rogers amical et pacifique des débuts…
Transition complète animée
Encore plus ?…
Après avoir ciblé zone par zone, il peut être intéressant de passer la dernière image obtenue dans un img2img intégral (qui peut rattraper des jonctions de zones qui commençaient à manquer de cohérence) avec un denoise-strength pas trop fort (0.5)
« a red general in a cyberpunk city by night, holds a energy weapon with blue laser »
Pour comparaison, voici ce que donne le même prompt/paramètres, mais sur la photo de départ:
STOP !
« A bride in a red wedding dress holds a blue flower bouquet in front of a night club »
Making-Of
Pour faire cet article avec environ 15 images publiées, entre 100 et 200 essais intermédiaires ont été nécessaires pour sélectionner les plus convenables.
Quelques résultats qui se rapprochent de la photo, mais à y regarder de plus près pas vraiment… (recherche simplement par raffinement du prompt et recherche de bonne seed avec Stable-Diffusion de base sans autre outils)
Cavalier dans la nature
txt2img.py --prompt "Photograph of a serious rider on his horse, in pine forest, crossing a stream, blue sky, rocky mountains on the horizon, National Geographic, Canon EOS 5D, 4k, detailed" --ckpt sd-v1-4.ckpt --n_samples 1 --n_iter 1 --precision full --W 704 --H 512 --ddim_steps 40 --scale 6.7
# recherche de seed entre 100000 et 100026
# Variation de prompte entre "stream", "snow", "spring flowers"
Chiens à la plage et ailleurs
Photoréaliste au niveau des textures ne veut pas dire réaliste biologiquement, selon les paramètres (scale 4.7 -> 6.7 -> 7.7, prompts variés autour de « Photograph of a fluffy labrador dog running and jumping on the beach, sand texture, floppy ears, catching a red ball, sunny sky, National Geographic, Canon EOS 5D, 4k, depth of field, detailed« , seed {1,2}00003 et suivants)
« On me dit que je ressemble à Alain de loin »
« à Alain Delon ? »
« non non, de loin »
(l’IA a confondu à moitié avec Patrick Dewaere non ?)
« studio Harcourt », « Polaroid », « Canon EOS 5D ».
Tour du monde des Bibliothéquaires
« Portrait of a {French,Italian,German…} librarian woman, Canon EOS 5D » seed 100003
Les yeux sont toujours ratés quel que soit le nombre d’itération, on va dire que c’est le lunettes (sauf les russes qui ont une meilleure vue apparemment).
Bizarrement, certaines nationalités changent brutalement de cadrage entre 50 et 150 itérations, dans ce cas j’ai mis les deux versions. Voire ne sont jamais cadré « en situation ».
Par défaut, les images de txt2img sont générés en itérant par dessus un bruit aléatoire (issu de la graine –seed passé en paramètre) dans l’espace « Latent ». Ces données ne sont pas manipulables et utilisable par défaut, à part choisir une graine aléatoire identique. img2img part d’une image source fournie par l’utilisateur mais la dérive aussi du bruit de l’espace latent sans contrôle.
Décalage
Avec un patch simple dans le code, il est possible de faire une première manipulation de cet espace latent, en contrôlant un décalage en X ou Y supplémentaire après la génération aléatoire.
À noter que la dimension de l’espace latent est 8 fois plus petit que l’image finale (optimisation de vitesse spécifique à Stable-Diffusion) et donc ces décalages ne sont pas très fluides et se font par saut de 8 pixels.
On remarque alors que l’image générée n’est pas simplement décalée sans changement: le réseau de neurone continue de réintepréter la génération selon ce qu’il a appris, par exemple un paysage de montagne sera souvent cadré avec 1/3 de ciel et 2/3 de montagnes; si elles sont trop décalées en haut ou en bas, alors elles seront métamorphosées en nuage ou en arbres:
les m
Un déplacement horizontal est un peu plus « naturel » mais va quand même faire beaucoup de métamorphoses:
Intensité
Un patch équivalent permet de multiplier le tensor de l’espace latent par une valeur entre -1 et +1; les valeurs négatives donnent un resultat totalement différent (similaire à un changement de seed ) , les valeurs proches de zéro donnent un vague brouillard uniforme, et entre 0.8 et 1.0 on assiste à une transition à partir de rien et un affinage des détails:
Interpolation
Une interpolation du tenseur de l’espace latent correspondant à deux seeds différentes permet de passer continûment d’une image à l’autre avec un prompt identique.
Bien que plus fluide que les décalages en X/Y, il reste toujours des sauts brusques lors de la création finale des « features » d’image, et l’interpolation ne donne pas un morphing uniforme: il y a de longues périodes de changements subtils puis de très courtes plages rassemblant de nombreuses métamorphoses.
Cette vidéos est assemblée à partir de différentes sections d’interpolation à taux variable (pour ne pas passer 10h à calculer 500 images où rien ne change):
Code
Un script simple pour faire un tour complet en X :
for k in $(seq 0 64); do
python scripts/txt2img.py --prompt 'A fantasy landscape, snow mountains on the horizon, ancient forest, bright day, concept-art' --seed 52 --skip_grid --ckpt sd-v1-4.ckpt --n_samples 1 --n_iter 1 --precision full --W 512 --H 512 --ddim_steps 50 --scale 7 --shift_latent_x $k;
done
Le patch de code :
--- a/scripts/txt2img.py
+++ b/scripts/txt2img.py
@@ -216,6 +216,17 @@ def main():
help="the seed (for reproducible sampling)",
)
parser.add_argument(
+ "--shift_latent_y",
+ type=int,
+ help="Scroll up the random latent space by N*8 pixels"
+ )
+ parser.add_argument(
+ "--shift_latent_x",
+ type=int,
+ help="Scroll left the random latent space by N*8 pixels"
+ )
+
+ parser.add_argument(
"--precision",
type=str,
help="evaluate at this precision",
@@ -273,6 +284,19 @@ def main():
if opt.fixed_code:
start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
+ if opt.shift_latent_y:
+ if start_code is None:
+ start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
+ print(f"Shifting tensor by {opt.shift_latent_y} blocs up")
+ start_code = torch.roll(start_code, opt.shift_latent_y, 2)
+
+ if opt.shift_latent_x:
+ if start_code is None:
+ start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
+ print(f"Shifting tensor by {opt.shift_latent_x} blocs left")
+ start_code = torch.roll(start_code, opt.shift_latent_x, 3)
+
+
precision_scope = autocast if opt.precision=="autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
Utilisation de img2img avec augmentation progressive du niveau de créativité autorisé:
« ‘A fantasy concept-art of haunted house by night, with dark dead trees, surounded by an old pine forest, princess in red dress standing, mysterious, oil paiting, illustration by Greg Rutkowski » et strength variant de 0.35 à 0.70
À partir du même générateur aléatoire de départ, variations sur le style d’un prompt unique « horreur cosmique Cthulu », dans les styles: illustration de carte de jeu, concept-art, dessin, peluche en laine et pate à modeler.