(Référence pour les incultes: https://fr.wikipedia.org/wiki/Hypoth%C3%A8se_de_Sapir-Whorf )
L’encodeur textuel t5xxl utilisé par Flux.1 est, comme tout bon LLM , entrainé sur de nombreux langages et pas juste en anglais (*). Mais pour un prompt identique simplement traduit dans différentes langues, comment se comporte l’image générée, est-elle aussi localisée vers le pays correspondant ?
(*) Enfin pas tant que ça: T5 a été entraîné sur Common_Crawl, qui contient 46% d’anglais, suivi de l’allemand, le russe, le japonais, le français, l’espagnol et le chinois, chacun représentant moins de 6 % des documents. Refs: https://en.wikipedia.org/wiki/T5_(language_model) et https://en.wikipedia.org/wiki/Common_Crawl
Testons depuis un prompt de base « Un homme en ville devant un monument célèbre » (à part l’anglais, les autres langues que je ne connais pas ont été traduites via Google-Translate), toujours sur la seed « 1 »
- Un homme en ville devant un monument célèbre
- A man in a city in front of a famous monument
- Un hombre en la ciudad frente a un monumento famoso.
- رجل في المدينة أمام نصب تذكاري مشهور
- Мужчина в городе перед известным памятником
- 유명한 기념물 앞에 있는 마을의 한 남자
- 有名な記念碑の前に立つ町の男性
- ሓደ ሰብኣይ ኣብ ከተማ ኣብ ቅድሚ ፍሉጥ ሓወልቲ (Tigrinia, parlé en Ethiopie et Erythrée)
- Mwanamume mjini mbele ya mnara maarufu (Swahili)
- En man i stan framför ett berömt monument (Skölh Offenstrü… Suédois)
- Moški v mestu pred slavnim spomenikom (Slovène)
- Ένας άντρας στην πόλη μπροστά από ένα διάσημο μνημείο
- Ein Mann in der Stadt vor einem berühmten Denkmal
- Bir kishi shaharda mashhur yodgorlik oldida (Uzbek)
- 鎮上一個著名嘅紀念碑前面嘅男人 (Cantonese)















Bon… Apparemment, les Coréens et Japonais ont overfité sur les mangas, les Ouzbeks sont réincarnés en tapis, et les fameuses Hyènes Bleues de chines roulent en scooter. La version arabisante est quant à elle très fantasmée…
Enfin c’était peut-être pas de bol pour cette seed, testons avec la seed « 2 »… Alors, dans l’ordre « Français, arabe, Swahili, Uzbek, Cantonese »: Déjà on voit qu’en Français le « monument célèbre » a été spécialisé en Arc de Triomphe. Pour le reste….





… oui bon c’est mieux mais pas vraiment ce que j’avais demandé non plus. Ne parlons même pas du genre.
Conclusion partielle: Dans les langues européennes (sûrement les mieux représentées dans l’entrainement de l’encodeur) l’image générées est, à la fois pertinente pour le prompt, et plus ou moins légèrement localisée dans la géographie typique correspondante; Mais en s’éloignant pour des langues plus « exotiques », ne vont rester qu’une vague tendance stylistique et stéréotypée.
On peut quand même, probablement, s’en servir pour orienter certaines caractéristiques de l’image générées; plutot que de décrire textuellement un paysage suédois typique, il suffit d’écrire directement le prompt en suédois.
Compromis à 50%: bilingual
Maintenant, utilisons la puissance de l’embedding textuel pour faire des maths sur la langue, en mixant les deux prompts « langue1 + langue2 » pour donner un vecteur abstrait entre les deux.
Le plus simple est de simplement écrire les deux phrases concaténées dans le prompt « Bir kishi shaharda mashhur yodgorlik oldida Un homme en ville devant un monument célèbre« . Notre tapis brodé et jeune beauté en studio se sont transformés vers l’idée originale du prompt:


Un homme en ville devant un monument célèbre
Prompt Interpolation
Avec le node ComfyUI « ConditioningAverage » on peut aussi écrire les deux prompts séparément en faire la moyenne mathématique, en réglant la pondération.
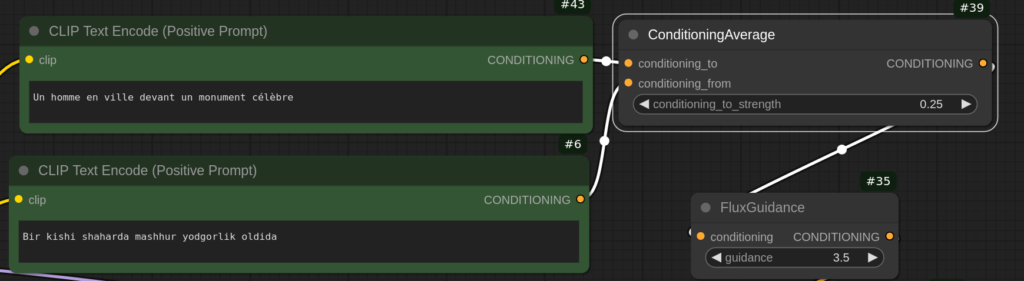
En réglant le taux d’ouzbekitude on peut varier assez continûment de 12% à 75% de français par rapport à l’Ouzbek (à 10% de français on est encore sur le tapis, à 12% on a déjà un humain, et à partir de 42% on a la composition habituelle personnage de dos).






Malgré ça, est-ce que ça ressemble à Samarcande ? Les médersa du Régistan n’ont pas ce gros bulbe sur le dessus.
Bien sûr on peut aussi mélanger Uzbek et Swahili pour voir ce que ça donne (seed 2 cette fois, qui a déjà des humains photographiques de base, même si la composition n’était pas bonne):



(et je doute que ça soit des tenues traditionnelles représentatives non plus…)
Pour forcer le respect du prompt initial, on va y rajouter 30% de prompt français (celui plus haut devant l’Arc de Triomphe) (à 12% il ne se passe quasiment rien), on a maintenant:



Bon maintenant il n’y a plus de monument particulièrement notable. Donc pas d’incohérence architecturale flagrante… Pas de pierre, pas de palais. Pas de Palais… pas de palais.




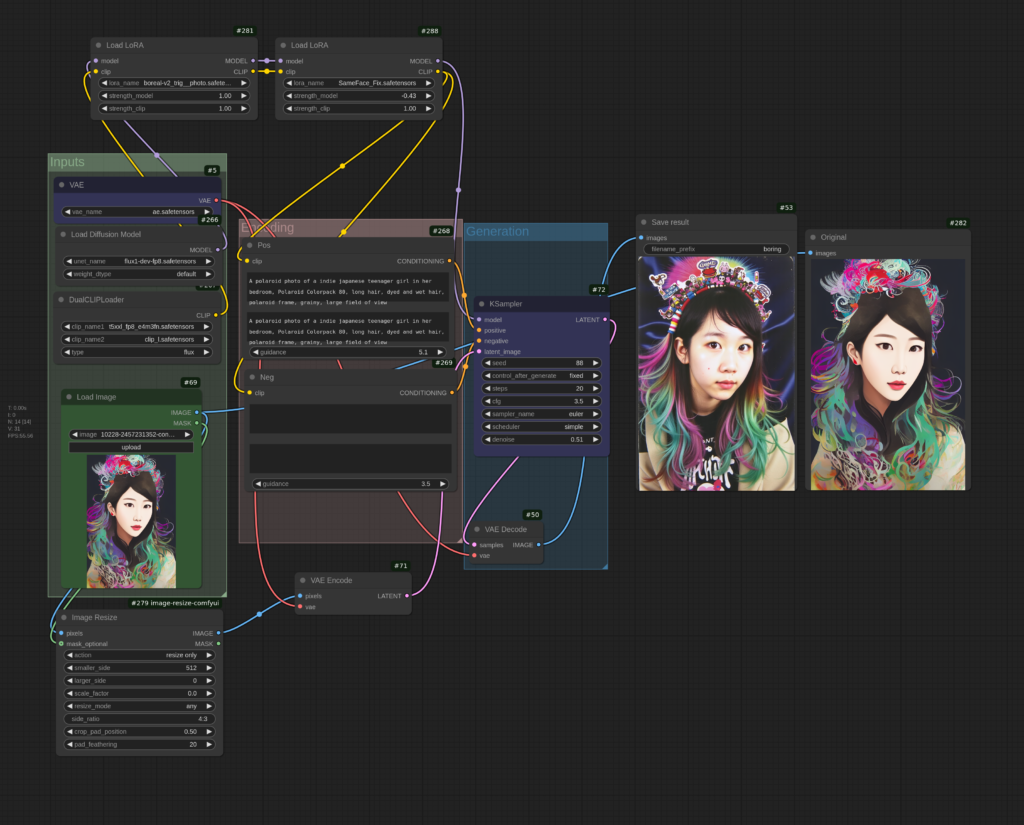









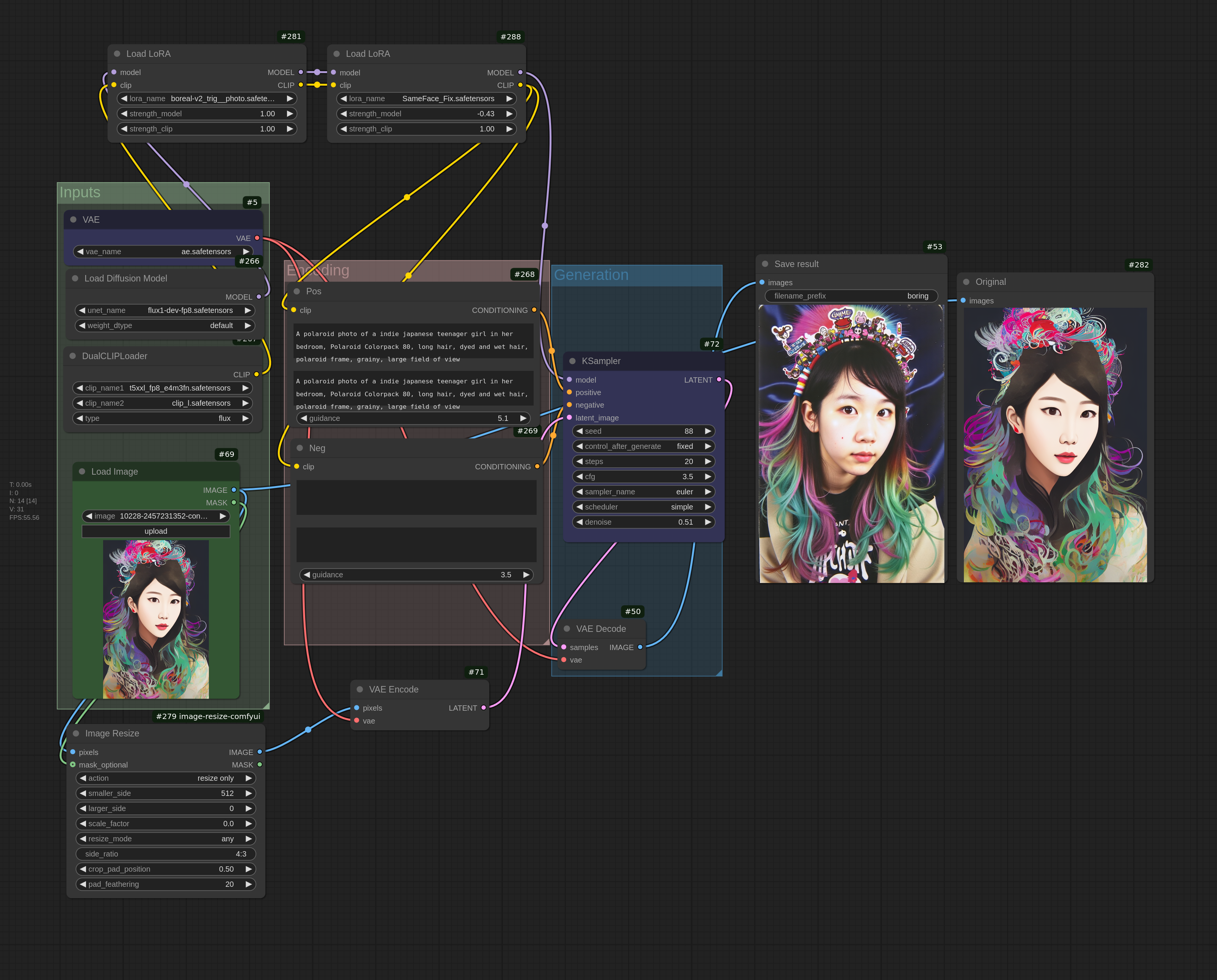{kind=link}