Autour de « recursive fractal bird, pencil art, black and white » et « ‘fractal bird, ink line art, black and white«












Et une interpolation animée:
Autour de « recursive fractal bird, pencil art, black and white » et « ‘fractal bird, ink line art, black and white«
Et une interpolation animée:
Par défaut, les images de txt2img sont générés en itérant par dessus un bruit aléatoire (issu de la graine –seed passé en paramètre) dans l’espace « Latent ». Ces données ne sont pas manipulables et utilisable par défaut, à part choisir une graine aléatoire identique. img2img part d’une image source fournie par l’utilisateur mais la dérive aussi du bruit de l’espace latent sans contrôle.
Avec un patch simple dans le code, il est possible de faire une première manipulation de cet espace latent, en contrôlant un décalage en X ou Y supplémentaire après la génération aléatoire.
À noter que la dimension de l’espace latent est 8 fois plus petit que l’image finale (optimisation de vitesse spécifique à Stable-Diffusion) et donc ces décalages ne sont pas très fluides et se font par saut de 8 pixels.
On remarque alors que l’image générée n’est pas simplement décalée sans changement: le réseau de neurone continue de réintepréter la génération selon ce qu’il a appris, par exemple un paysage de montagne sera souvent cadré avec 1/3 de ciel et 2/3 de montagnes; si elles sont trop décalées en haut ou en bas, alors elles seront métamorphosées en nuage ou en arbres:
Un déplacement horizontal est un peu plus « naturel » mais va quand même faire beaucoup de métamorphoses:
Un patch équivalent permet de multiplier le tensor de l’espace latent par une valeur entre -1 et +1; les valeurs négatives donnent un resultat totalement différent (similaire à un changement de seed ) , les valeurs proches de zéro donnent un vague brouillard uniforme, et entre 0.8 et 1.0 on assiste à une transition à partir de rien et un affinage des détails:
Une interpolation du tenseur de l’espace latent correspondant à deux seeds différentes permet de passer continûment d’une image à l’autre avec un prompt identique.
Un test d’interpolation naïve linéaire ne donne pas de résultat (90% de la plage visitée est un brouillard vide), il faut utiliser une « interpolation sphérique », voir la fonction « slrep » de https://github.com/nateraw/stable-diffusion-videos/commit/a1244dc452f1bc2dd78890840b13e273913127d7
Bien que plus fluide que les décalages en X/Y, il reste toujours des sauts brusques lors de la création finale des « features » d’image, et l’interpolation ne donne pas un morphing uniforme: il y a de longues périodes de changements subtils puis de très courtes plages rassemblant de nombreuses métamorphoses.
Cette vidéos est assemblée à partir de différentes sections d’interpolation à taux variable (pour ne pas passer 10h à calculer 500 images où rien ne change):
Un script simple pour faire un tour complet en X :
for k in $(seq 0 64); do
python scripts/txt2img.py --prompt 'A fantasy landscape, snow mountains on the horizon, ancient forest, bright day, concept-art' --seed 52 --skip_grid --ckpt sd-v1-4.ckpt --n_samples 1 --n_iter 1 --precision full --W 512 --H 512 --ddim_steps 50 --scale 7 --shift_latent_x $k;
doneLe patch de code :
--- a/scripts/txt2img.py
+++ b/scripts/txt2img.py
@@ -216,6 +216,17 @@ def main():
help="the seed (for reproducible sampling)",
)
parser.add_argument(
+ "--shift_latent_y",
+ type=int,
+ help="Scroll up the random latent space by N*8 pixels"
+ )
+ parser.add_argument(
+ "--shift_latent_x",
+ type=int,
+ help="Scroll left the random latent space by N*8 pixels"
+ )
+
+ parser.add_argument(
"--precision",
type=str,
help="evaluate at this precision",
@@ -273,6 +284,19 @@ def main():
if opt.fixed_code:
start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
+ if opt.shift_latent_y:
+ if start_code is None:
+ start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
+ print(f"Shifting tensor by {opt.shift_latent_y} blocs up")
+ start_code = torch.roll(start_code, opt.shift_latent_y, 2)
+
+ if opt.shift_latent_x:
+ if start_code is None:
+ start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
+ print(f"Shifting tensor by {opt.shift_latent_x} blocs left")
+ start_code = torch.roll(start_code, opt.shift_latent_x, 3)
+
+
precision_scope = autocast if opt.precision=="autocast" else nullcontext
with torch.no_grad():
with precision_scope("cuda"):
Utilisation de img2img avec augmentation progressive du niveau de créativité autorisé:
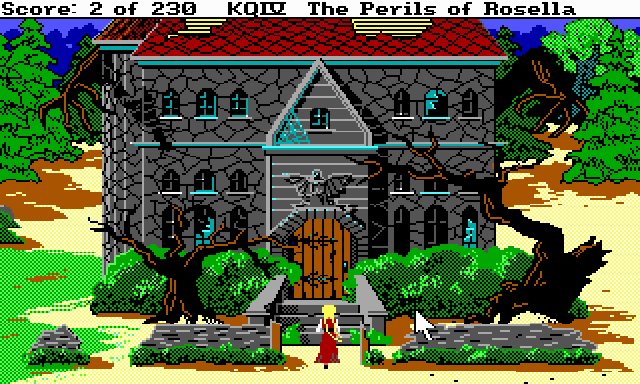
« ‘A fantasy concept-art of haunted house by night, with dark dead trees, surounded by an old pine forest, princess in red dress standing, mysterious, oil paiting, illustration by Greg Rutkowski » et strength variant de 0.35 à 0.70




À partir du même générateur aléatoire de départ, variations sur le style d’un prompt unique « horreur cosmique Cthulu », dans les styles: illustration de carte de jeu, concept-art, dessin, peluche en laine et pate à modeler.





Idem mais pour son petit frère:






Une sélection de 9 parmi une centaines de générations.









Dans des styles plus méchaniques:




Image source:

Images générées via des variations de prompt de type « A Dragon flying in the sky above a fantasy landscape, snow mountains on the horizon, ancient forest, concept art », parfois en laissant plus ou moins de liberté de déviation de l’image source, ou en itérant plusieurs fois par dessus une image générée à améliorer:
(9 images extraites parmi les 90 générées)









Initialement guidé par cet immonde photomontage de départ:

mais dont il ne reste plus rien à la fin:











« A cat in knight armor » et autres variations










Lion


Dalmatien et Chihuaha



Le renard est de retour

